2.4 Arbeit mit Strings
-
2.4.1 Bearbeiten von Strings: Left$, Right$, Mid$, Trim$, ReplaceStr$, String$, InStr, LEN, CountStr, +, GetTextWitdh, GetTextHeight
Suchen in Text-Objekten - Neue Funktionen in R-BASIC 1.02
2.4.2 Vergleichen von Strings: <, <=, >, >=, =, <>, CompStr
2.4.3 Konvertierungsfunktionen: Bin$, Chr$, Hex$, Str$, StrLocal$, ASC, VAL, ValLocal, Convert$
Erweitere Konvertierfunktionen für macOS & Linux - Neue Funktionen in R-BASIC 1.02
^
2.4.1 Bearbeiten von Strings
Zeichenketten wie z.B. "Hallo Welt" werden in BASIC als Strings bezeichnet. Die Verarbeitung von Strings ist eine der grundlegenden Fähigkeiten von R-BASIC. Die Grundlagen zur Verwendung von Strings und von Stringvariablen finden Sie im Kapitel 2.2.3 (Stringtypen und Stringausdrücke).Left$
Die Funktion Left$( A$, N ) (Left - links) liefert die N ersten (linken) Zeichen des Strings A$.Syntax: <stringVar> = Left$( A$, N )
Parameter: A$: ein Stringausdruck
N: numerischer Ausdruck, Anzahl der Zeichen
Beispiel:
L$ = Left$("Paulchen N.", 4) ' Entspricht L$ = "Paul"
L$ = Left$(L$, 1) ' Macht aus "Paul" ein "P"
Right$
Die Funktion Right$(A$, N) (Right - rechts) liefert die N letzten (rechten) Zeichen des Strings A$.Syntax: <stringVar> = Right$( A$, N)
Parameter: A$: ein Stringausdruck
N: numerischer Ausdruck, Anzahl der Zeichen
Beispiel:
R$ = Right$("Paulchen N.", 4) ' Entspricht R$ = "n N."
R$ = Right$ (Left$("ABCDEF", 4), 2 ) ' liefert "CD"
Mid$
Die Funktion Mid$( A$, P, N) (Middle - Mitte) liefert N Zeichen ab der Position P in einem String.Syntax: <stringVar> = Mid$( A$, P, N)
<stringVar>= Mid$(A$, P)
Parameter: P: Erste Zeichenposition, die kopiert werden soll.
N: Anzahl der Zeichen die kopiert werden sollen
ohne N: Alle restlichen Zeichen werden kopiert
Beispiele:
X$ = Mid$("OTTOKAR", 3, 4) ' liefert "TOKA"
X$ = Mid$("OTTOKAR", 5) ' liefert "KAR"
Trim$
Die Funktion Trim$(A$ [,mode]) entfernt Leerzeichen und Tabs am Anfang und / oder am Ende der Zeichenkette.Syntax: <stringVar> = Trim$(A$[,mode])
Parameter: mode: numerischer Ausdruck, bestimmt ob Leerzeichen und Tabulatoren am Anfang (mode = 1), Am Ende (mode =2) oder beiden (mode = 3, Defaultwert) entfernt werden sollen.
A$: Stringausdruck, der bearbeitet werden soll.
Beispiel:
X$ = Trim$(" Paul ") ' liefert "Paul"
X$ = Trim$(" Paul ", 1) ' liefert "Paul "
X$ = Trim$(" Paul ", 2) ' liefert " Paul"
ReplaceStr$
Die Funktion ReplaceStr$(s$, a$, b$) ersetzt jedes Auftreten des Strings a$ in s$ durch b$.Syntax: <stringVar> = ReplaceStr$(s$, a$, b$)
<stringVar>: Stringvariable
s$: String, der durchsucht werden soll
a$: String, der ersetzt werden soll
b$: String, der a$ ersetzen soll
b$ darf genauso lang, länger oder kürzer als a$ sein. Ist b$ ein Leerstring, wird jedes Auftreten von a$ gelösch
Beispiele:

String$
Die Funktion String$(N, A$) vervielfacht Zeichenkettenausdrücke.Syntax: <stringVar> = String$( N, A$)
Parameter: N: numerischer Ausdruck, Anzahl der Vervielfachungen
A$: Stringausdruck, der vervielfacht werden soll
Beispiel:
X$ = String$(4, "X") ' liefert "XXXX"
X$ = String$(2, Left$("KOMA", 2)) ' liefert "KOKO"
InStr
Die Funktion InStr(A$, B$) (d.h. In-String) ermittelt die Position, ab welcher A$ in B$ enthalten ist.Syntax: <numVar> = InStr(A$, B$)
Parameter: A$ : String-Ausdruck: der zu findende String
B$ : String-Ausdruck: String, der A$ enthalten soll
Beispiel:
DIM Anz
Anz = InStr("ul", "Paula") ' liefert 3
Anz = InStr("lala", "Paula") ' liefert Null
- Groß- und Kleinbuchstaben werden unterschieden
- Ist der String nicht oder nicht vollständig enthalten, liefert InStr den Wert Null.
- Ist einer der beiden Strings ein Leerstring (""), liefert InStr den Wert Null.
LEN
Die Funktion LEN (Length - Länge) liefert die Länge des Strings, d.h. die Anzahl der enthaltenen Zeichen.Syntax: <numVar> = LEN(A$)
Parameter: A$ String-Ausdruck
Beispiel:
DIM A
A = LEN("Paula") ' liefert 5
A = LEN("") ' liefert Null
CountStr
Die Funktion CountStr(A$, B$) zählt, wie oft A$ in B$ enthalten ist.Syntax: <numVar> = CountStr(A$, B$)
Parameter: A$ : String-Ausdruck: der zu findende String
B$ : String-Ausdruck: String, der A$ enthalten soll
Beispiel:
DIM N
N = CountStr("ul", "Paula") ' liefert 1
N = CountStr("a", "Paula") ' liefert 2
N = CountStr("aha", "Hahaha") ' liefert 1
- Groß- und Kleinbuchstaben werden unterschieden
- Ist der String nicht oder nicht vollständig enthalten, liefert CountStr den Wert Null.
- Ist einer der beiden Strings ein Leerstring (""), liefert CountStr den Wert Null.
- Beachten Sie Beispiel 3! Buchstaben, die bereits gefunden wurden, werden nicht noch einmal berücksichtigt.
Stringoperation +
Die Operation + verbindet zwei Strings.Syntax: <stringVar> = A$ + B$
Parameter: A$, B$: Beliebige Stringausdrücke
Beispiel:
A$ = "Paul" + " " + "Müller" ' liefert "Paul Müller"
A$ = "->" + Left$("Paul", 2) + "<-" ' liefert "->Pa<-"
GetTextWitdh, GetTextHeight
GetTextWidth berechnet die Breite (in Pixeln), die ein String bei Ausgabe auf den Bildschirm benötigt. GetTextHeight berechnet die entsprechende Höhe (in Pixeln). Die beiden Routinen sind in allen Fontmodi (Fixed-, Block- und GEOS-Font-Modus, siehe Handbuch Spezielle Themen, Kapitel 2), anwendbar. Sie eignen sich zum Beispiel um einen Text zentriert an eine bestimmte Position zu drucken.Syntax: <numVar> = GetTextWidth( "Text" )
<numVar> = GetTextHeight( "Text" )
Beachten Sie, dass im GEOS-Font-Modus (Routine FontSetGeos, siehe Handbuch Spezielle Themen, Kapitel 2.4) die Breite und Höhe wirklich nur den von den Buchstaben überdeckten Bereich umfassen. Der als Texthintergrund eingefärbte Bereich ist im Allgemeinen merklich größer. Das kann insbesondere dann verwirrend sein, wenn Sie einen Rahmen um einen Text zeichnen wollen.
Die folgende Routine zeichnet einen Rahmen um einen Text. Im GEOS-Font-Modus machen wir den Rahmen etwas breiter (4 Pixel) und höher (8 Pixel) und berücksichtigen, dass der eigentliche Buchstabe immer etwas rechts unterhalb der in Print atXY angegebenen Position gezeichnet wird. Die notwendigen Werte für die Verschiebung und die Vergrößerung des Rahmens hängen etwas vom eingestellten Font und der Schriftgröße ab.
SUB DrawTextFramed(t$ as String, x, y AS REAL)
DIM w, h
Print atXY x, y; t$
w = GetTextWidth(t$)
h = GetTextHeight(t$)
IF printfont.type = FT_GEOS THEN
x = x - 1
y = y + 2
w = w + 4
h = h + 8
End IF
Rectangle x-1, y-1, x+w, y+h, LIGHT_CYAN
END SUB
^
2.4.2 Vergleichen von Strings
Vergleichsoperatoren
Die Standard-Vergleichsoperatoren ( <, <=, >, >=, =, <> ) stehen auch für Zeichenketten (Strings) zur Verfügung. Die Strings werden dabei Zeichen für Zeichen verglichen, wobei ausschließlich die ASCII-Codes der einzelnen Zeichen berücksichtigt werden. Das heißt z.B. dass Umlaute entsprechend ihrer Position in der ASCII-Code-Tabelle (also noch hinter z) gewertet werden. Für lexikalisch korrekte Vergleiche verwenden Sie bitte die unten beschriebene Funktion CompStr.Syntax: A$ < B$
A$ <= B$ usw.
Parameter: A$, B$ String-Ausdrücke, die verglichen werden sollen
Ergebnis: Wahr (TRUE, numerischer Wert: -1)
oder Falsch (FALSE, numerischer Wert: 0)
Beispiel:
IF A$ >= "Paul" THEN ...
IF A$ <> Left$("Paul", 2) THEN ...
Tipp: String-Vergleiche arbeiten auch mit den logischen Operatoren zusammen. Da Vergleiche höher priorisiert sind, benötigt man hier meist keine Klammern.
Beispiele:
IF NAME$ = "Müller" OR NAME$ = "Meier" THEN ... IF A$ < B$ OR A$ < C$ THEN ...
DIM A As Real
DIM Name$ as String
A = (Name$ = "Müller") ' A wird -1 (wahr), wenn Name$ = "Müller" ist,
' andernfalls wir A Null
CompStr
Die Funktion CompStr (Compare Strings, d.h. vergleiche Zeichenketten) vergleicht zwei Strings entsprechend ihrer Anordnung im Wörterbuch. Dabei gelten folgende Regeln:- Umlaute reihen sich ein
- Großbuchstaben stehen bei ansonsten gleichen Strings vor den Kleinbuchstaben. Beispiel: "Schwimmen" steht vor "schwimmen"
- Kürzere Strings stehen bei Gleichheit mit längeren Strings vorn. Beispiel: "Paul" steht vor "Paula".
Syntax: <numVar> = CompStr(A$, B$)
Parameter: A$, B$ String-Ausdrücke, die verglichen werden sollen
Ergebnis: -1 wenn A$ < B$, d.h. A$ steht vor B$ im Wörterbuch
0 wenn A$ = B$, d.h. A$ und B$ stehen an gleicher Stelle im Wörterbuch. Dann sind beide Strings identisch.
+1 wenn A$ > B$, d.h. A$ steht nach B$ nach Wörterbuch
Beispiel:
Dim V as Real IF CompStr(A$, B$) > 0 THEN ... V = CompStr(A$, B$)
Achtung! Die Funktion verwendet länderspezifische Regeln. Es ist möglich, dass auf anderen, insbesondere auf nicht deutschen PC/GEOS-Systemen, andere Regeln bezüglich der Anordnung im Wörterbuch gelten. CompStr verwendet die auf dem jeweiligen PC/GEOS-System geltenden Regeln.
^
2.4.3 Konvertierungsfunktionen
Konvertierung Zahl zu String
Bin$
Die Funktion Bin$ (Binär Konvertierung) wandelt eine Ganzzahl in ihre binäre Darstellung (zur Basis 2) um. Nichtganzzahlige Argumente x werden gerundet. Negative Zahlen werden ebenfalls korrekt behandelt.Syntax: <stringVar> = Bin$( x [,min[,max]])
Parameter: x: numerischer Ausdruck, Zahlenbereich DWord (32 Bit)
min: optional: Mindestanzahl auszugebender Binärziffern. Es werden bei Bedarf führen Nullen hinzugefügt.
max: optional: Maximalzahl auszugebender Binärziffern. Führende Stellen werden gerundet. min und max dürfen im Bereich von 1 bis 32 liegen
Beispiel:
A$ = Bin$(5) ' A$ = "101"
A$ = Bin$(18) ' A$ = "10010"
A$ = Bin$(5, 4) ' A$ = "0101"
A$ = Bin$(18, 4, 4) ' A$ = "0010"
' das fünfte Bit wird ignoriert
Chr$
Die Funktion Chr$(x) (Character - Zeichen) liefert das Text-Zeichen, das zum ASCII-Code x gehört. Chr$(0) liefert einen leeren String.Syntax: <stringVar> = Chr$(x)
Parameter: x: numerischer Ausdruck
Beispiel:
A$ = Chr$(65 + 1) ' Entspricht A$ = "B"
A$ = "a" + Chr$(180) + "b" A$ = "a\180b"
Hex$
Die Funktion Hex$ (Hexadezimal Konvertierung) wandelt eine Ganzzahl in ihre hexadezimale Darstellung (zur Basis 16) um. Nichtganzzahlige Argumente x werden gerundet. Negative Zahlen werden ebenfalls korrekt behandelt.Syntax: <stringVar> = Hex$(x [,min [,max]])
Parameter: x: numerischer Ausdruck, Zahlenbereich DWord (32 Bit d.h. 8 Hex-Stellen)
min: optional: Mindestanzahl auszugebender Hex-Ziffern. Es werden bei Bedarf führen Nullen hinzugefügt.
max: optional: Maximalzahl auszugebender Hex-Ziffern. Führende Stellen werden gerundet.
min und max dürfen im Bereich von 1 bis 8 liegen
Beispiele:
A$ = Hex$(11) ' A$ = "B" A$ = Hex$(11, 2) ' A$ = "0B" A$ = Hex$(764, 2) ' A$ = "2FC" A$ = Hex$(764, 2, 2) ' A$ = "FC" A$ = Hex$(764, 4, 4) ' A$ = "02FC"
Str$
Die Funktion Str$(x) (String - Zeichenfolge) konvertiert eine Zahl in eine Zeichenkette, genau so, als ob Sie die Zahl mit PRINT auf den Bildschirm ausgeben. Als Dezimaltrennzeichen wird immer der Punkt '.' verwendet.Syntax: <stringVar> = Str$(x)
Parameter: x: numerischer Ausdruck
Beispiel:
A$ = Str$( 12+3 ) ' Entspricht A$ = " 15 "
StrLocal$
Die Funktion StrLocal$(x) (String Local) konvertiert eine Zahl in eine Zeichenkette unter Verwendung der lokal (auf dem aktuellen Rechner) gültigen Einstellungen für Dezimal- und Tausender-Trennzeichen. Verwenden Sie diese Konvertierungs-Funktion wenn Sie dem Nutzer seine "gewohnte" Zahlendarstellung präsentieren wollen.Syntax: <stringVar> = StrLocal$(x)
Parameter: x: numerischer Ausdruck
Beispiel:
A$ = StrLocal$(9.82347E5 ) ' Liefert auf den meisten
' deutschen Computern " 98.234,7"
Hinweis: Das Zahlenformt der konvertierten Zahl kann mit der System-Variablen numberFormat beeinflusst werden.
Konvertierung String zu Zahl
ASC
Die Funktion ASC (von ASCII) liefert den ASCII-Code des ersten Zeichens des Strings. ASC("") (Leerstring) liefert Null.Syntax: <numVar> = ASC(A$)
Parameter: A$: String-Ausdruck
Beispiel:
X = ASC("Auto") ' liefert 65, den ASCII-Code von A
VAL
Die Funktion VAL (Value - Wert) wandelt eine Zeichenkette in die entsprechende Zahl um. Entspricht die Zeichenkette keiner Zahl, versucht VAL seine Aufgabe "so gut wie möglich" zu erfüllen und konvertiert so viele Zeichen wie es finden kann - findet es gar keine gültigen Zeichen, liefert es Null.Syntax: <numVar> = VAL(A$)
Parameter: A$: String-Ausdruck
Beispiel:
X = VAL("-12.8") ' Entspricht X = -12.8
X = VAL("Paul") ' liefert Null.
ValLocal
Die Funktion ValLocal wandelt eine Zeichenkette in die entsprechende Zahl um. Dabei werden die lokal (auf dem aktuellen Computer) eingestellten Dezimal- und Tausendertrennzeichen erwartet. Verwenden Sie diese Konvertierungs-Funktion, wenn der Nutzer eine Zahl in der für ihn vertrauten Weise eingeben soll.Syntax: <numVar> = ValLocal(A$)
Parameter: A$: String-Ausdruck
Beispiel:
X = ValLocal("12.824,2") ' funktioniert für die meisten
' deutschen Computer und liefert
' Zwölftausendachthundertvierundzwanzig Komma Sieben
Zeichensätze konvertieren
Convert$
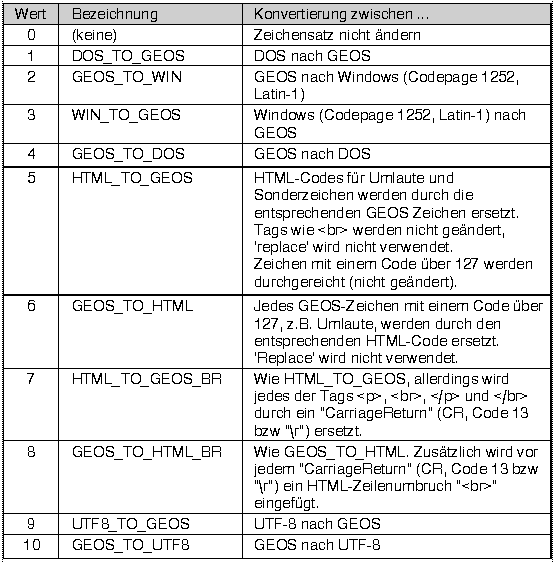
GEOS verwendet einen anderen Zeichensatz als DOS oder Windows, d.h. die ASCII-Codes für bestimmte Zeichen ( ASCII-Code >= 128) unterscheiden sich und es gibt Zeichen in jedem Zeichensatz, die in den anderen Zeichensätzen nicht darstellbar sind. Die Funktion Convert$() übernimmt die Konvertierung zwischen den verschiedenen Zeichensätzen und ersetzt Codes, die im neuen Zeichensatz nicht darstellbar sind.- Syntax: <stringVar> = Convert$(A$, mode [, replace])
- Parameter: A$: Stringausdruck, der konvertiert werden soll
- mode: Bestimmt, zwischen welchen Zeichensätzen konvertiert werden soll. Siehe Tabelle unten.
- replace: ASCII-Code des Ersatz-Zeichens, falls ein Zeichen nicht konvertierbar ist. 'replace' ist optional.
- - Wird 'replace' nicht angegeben, wird das Standardzeichen '_' verwendet.
- - Wird für 'replace' Null angegeben, werden nicht konvertierbare Zeichen gelöscht.
- replace: ASCII-Code des Ersatz-Zeichens, falls ein Zeichen nicht konvertierbar ist. 'replace' ist optional.
Für 'mode' stehen folgende Werte zur Verfügung:
Jeder der Werte aus der Tabelle oben kann mit den folgenden Flags kombiniert werden, indem die Werte addiert oder logisch OR kombiniert werden. Außerdem können die Flags auch allein verwendet werden.
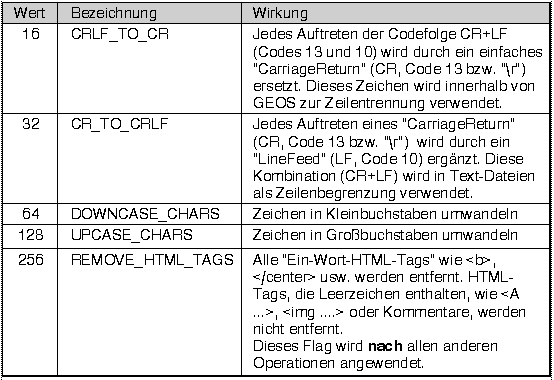
X$ = Convert$(A$, DOS_TO_GEOS)
X$ = Convert$(A$, GEOS_TO_DOS OR CR_to_CRLF)
X$ = Convert$(A$, WIN_TO_GEOS + DOWNCASE_CHARS, ASC("#"))
X$ = Convert$(A$, UPCASE_CHARS)
X$ = Convert$(A$, HTML_TO_GEOS_BR + CRLF_TO_CR)
- Bei der Konvertierung zwischen GEOS- und DOS-Zeichensatz sowie bei der Umwandlung zwischen Klein- und Großbuchstaben werden die lokalen Einstellungen des Computers benutzt.
- Das Ersetzen von HTML-Tags lässt sich auch vorteilhaft mit der Funktion RepalceStr$ erledigen.
- Wenn Sie einen HTML-Text haben, der ANSI (Codepage 1252, Latin-1) oder UTF-8 kodiert ist (also gültige Zeichen mit einem Code > 127 enthält) müssen sie vorher die entsprechende Konvertierungsroutine aufrufen.
B$ = Convert$(A$, WIN_TO_GEOS) X$ = Convert$(B$, HTML_TO_GEOS)
B$ = Convert$(A$, UTF8_TO_GEOS) X$ = Convert$(B$, HTML_TO_GEOS)
convertError
Findet Convert$ im Modus UTF8_TO_GEOS am Ende des Strings einen unvollständigen UTF-8-Code (also z.B. nur 2 von 3 erforderlichen Bytes) so setzt es die Systemvariable convertError auf die Anzahl der gefundenen Bytes (im Beispiel also auf 2). Andernfalls setzt es convertError auf Null.Syntax: <numVar> = convertError
Diese Situation kann vorkommen, wenn Sie Text blockweise statt zeilenweise aus einer Datei lesen müssen, z.B. weil die Zeilen sonst zu lang sind. In diesem Fall können Sie den Dateizeiger folgendermaßen auf den Anfang des unvollständig gelesenen UTF-8-Zeichens zurücksetzen (beachten Sie das Minuszeichen!):
IF convertError THEN FileSetPos( fileVar, -convertError, TRUE ) END IF
^
Suchen in Text-Objekten - Neue Funktionen in R-BASIC 1.02
Erweitere Konvertierfunktionen für macOS & Linux - Neue Funktionen in R-BASIC 1.02